
Deployment topologies
🗓️ Last updated on March 11, 2025 | 6 | Improve this pageIntroduction
We often get the question from people who are adopting Microcks on the deployment topology: Where to deploy it and which personas to target? Microcks is modular and flexible, and it runs in many different ways. Having many options can make it unclear to novice users where to begin and how to get started.
In this article, we share our experience with different topologies or patterns we’ve seen adopted depending on organization maturity and priorities. Even if those patterns are presented in an ordered way, there’s no rule of thumb, and you may choose to go the other way around if it makes sense.
💡 There may be some other topologies we have missed here.
Please share them with the community if they help you be successful!
1. Global centralized instance
The first deployment topology that people often start with is the one of the Globally shared, centralized instance. In this topology, Microcks is deployed on a centralized infrastructure and can be accessed by many different teams. It allows discovering and sharing the same API mocks, sourced by one or many Git repositories. It can also be used to run tests on deployed API endpoints.
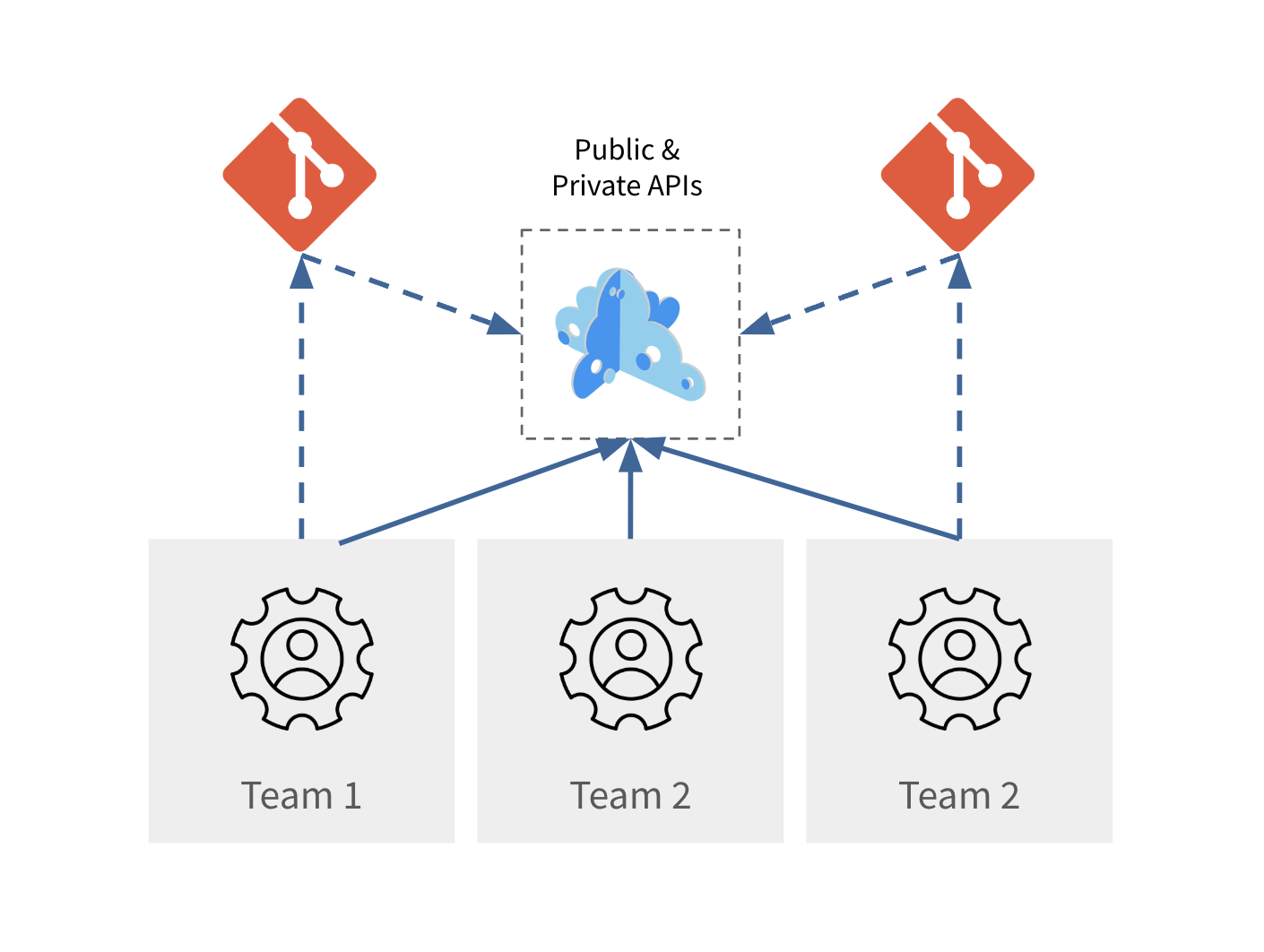
In such a topology, Microcks is always up and running and should be dimensioned to host an important number of users and APIs, with secured access, RBAC and segregation features turned on. As datasets and response times are instance-scoped settings, they cannot be customized for different use cases.
Benefits
✅ Easy to start with - just one deployment!
✅ Acts immediately as a natural catalog for all teams API
✅ Centralizes both mocks and tests with multiple versions and history
Concerns
🤔 Security and RBAC configuration
🤔 Needs proper dimensioning
🤔 Too many APIs? Maybe the private ones are not “that important”…
❌ Different mock datasets for different use-cases
❌ Different API response times for different use-cases
2. Local instances
As a developer, you may want to use Microcks directly on your laptop during your development iterations and within your unit tests with the help of Testcontainers. Running it directly in your IDE is also possible via DevContainers. This eases the pain in managing dependencies and gives you fast feedback.
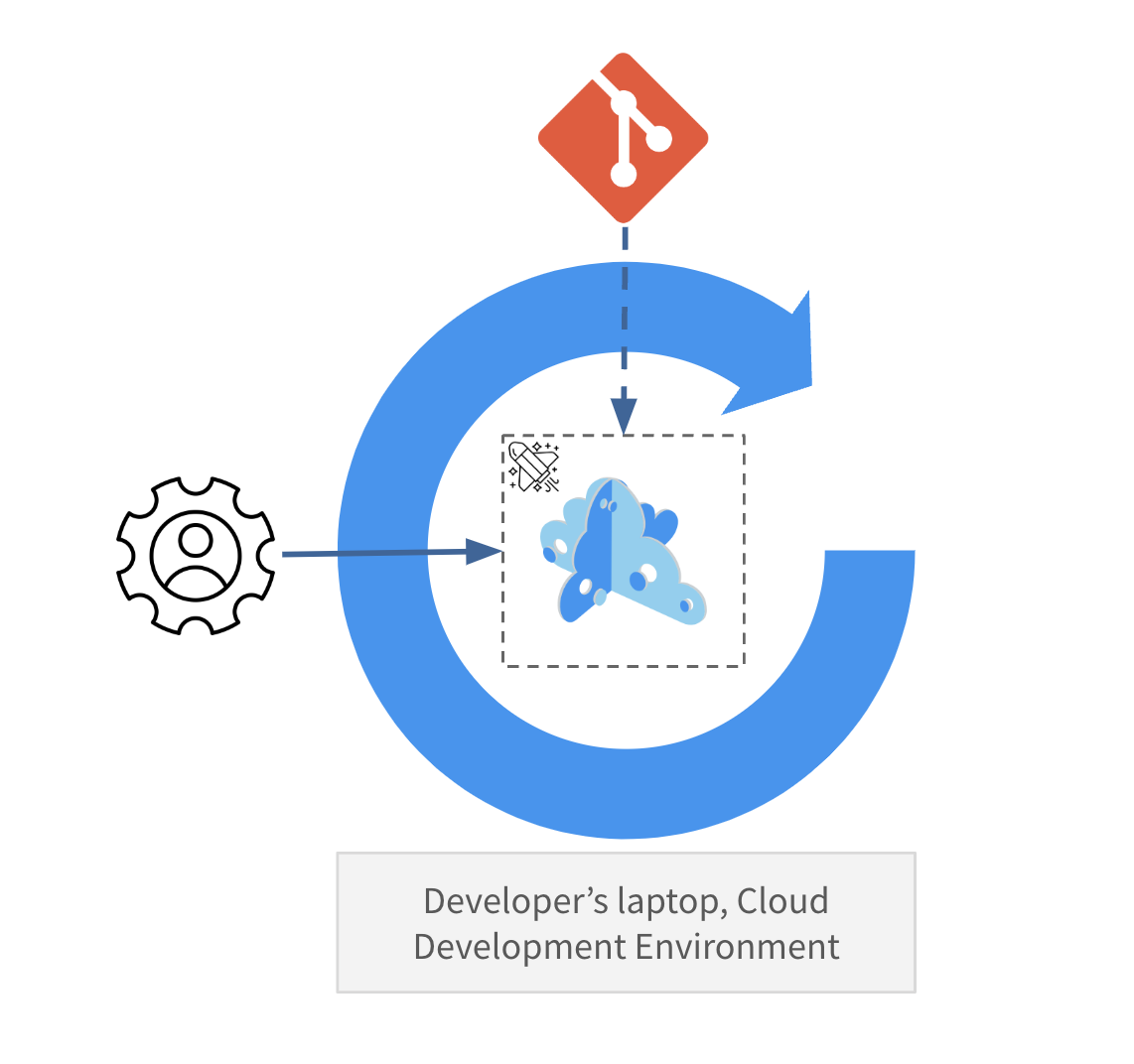
In such a topology, Microcks instances are considered “Ephemeral” and thus don’t keep history. They can be configured with custom datasets, but with the risk of drifting. Frequent synchronization needs to happen to avoid this.
Benefits
✅ Directly run in IDE or unit tests!
✅ Super fast iterations thanks to Shift-left
✅ Only the API you’re working on or the ones you need
✅ Project specific configuration: datasets, response times
Concerns
🤔 No history!
🤔 How to measure improvements?
🤔 How to be sure non-regression tests are also included?
🤔 Needs frequent sync to avoid drifts
❌ Limited connection to central infrastructure (eg: some message brokers)
3. Process-scoped instances
As an intermediate solution, we see more and more adopters deploying Microcks for scoped use cases in an “Ephemeral” way. The goal is to provide a temporary environment with mocked dependencies for: development teams, performance testing campaigns, Quality Assurance needs, training, partner onboarding,.. This approach can also be coined Sandbox-as-a-service: a way to provide testing environments on demand. It is typically integrated, orchestrated and controlled by workflows such as a long-running CI/CD pipeline or provisioning processes.
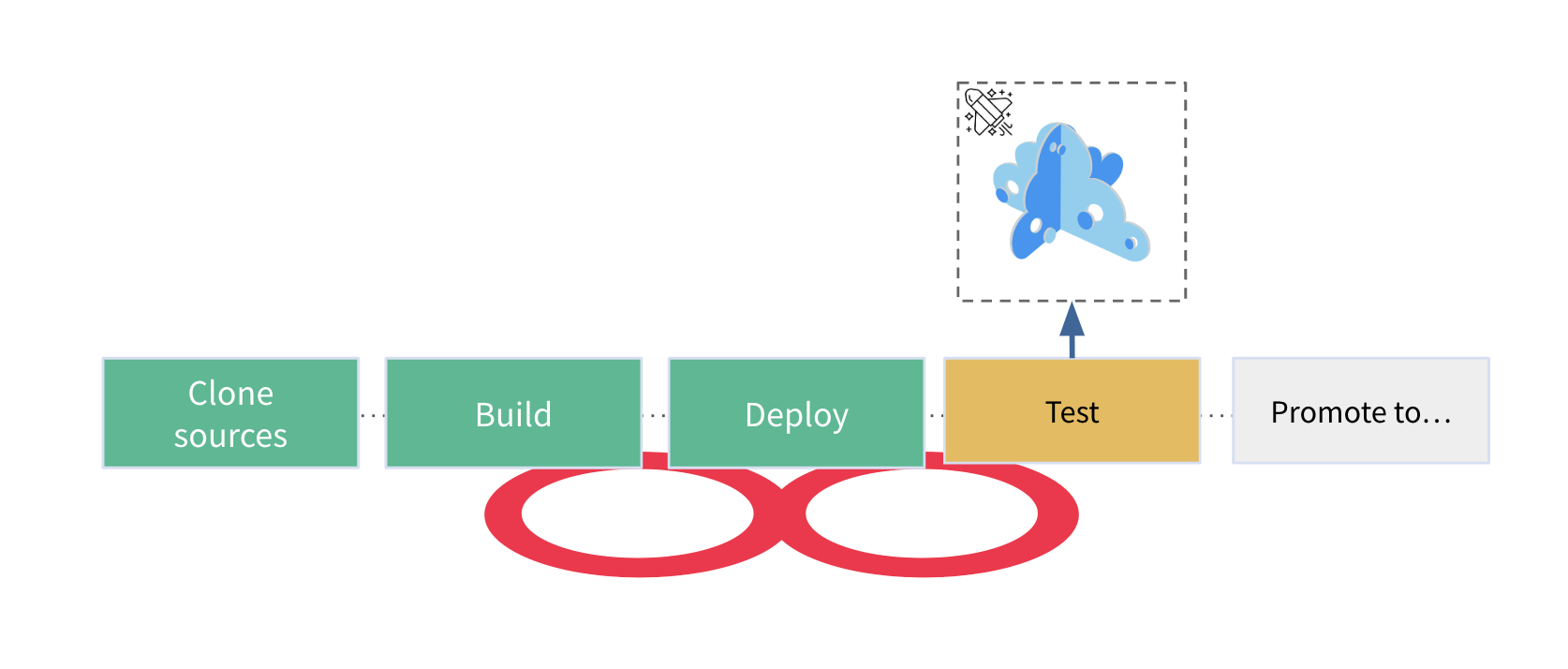
Those instances are considered “Ephemeral” or temporary, but it could be: minutes, days or even months. They allow fine-grained configuration and customization as they’re dedicated to one single use case or project/team. Depending on the use case, you may pay great attention to management automation, and that’s where Microcks Kubernetes Operator can make sense in a GitOps approach.
Benefits
✅ “Ephemeral”: saves money vs comprehensive environments
✅ Only the API you need (eg. your dependencies)
✅ Project specific configuration: datasets, response times
✅ Project specific access control
Concerns
🤔 No history!
🤔 No global or consolidated vision
🤔 Automation of the provisioning process
4. Regional instances
The final pattern to take into consideration is the Regional and scoped instances. This one can be used from the start in the case of a scoped-test adoption of Microcks: it presents more or less the same characteristics of the Globally shared, centralized instance, but you decide to restrict it to a specific scope in your organization. It could be for a functional domain, for an application, or whatever makes sense from a governance point of view. A regional instance will hold all the API mocks and tests for both public and private APIs and will be the reference to measure quality, improvements and to source some other catalogs.
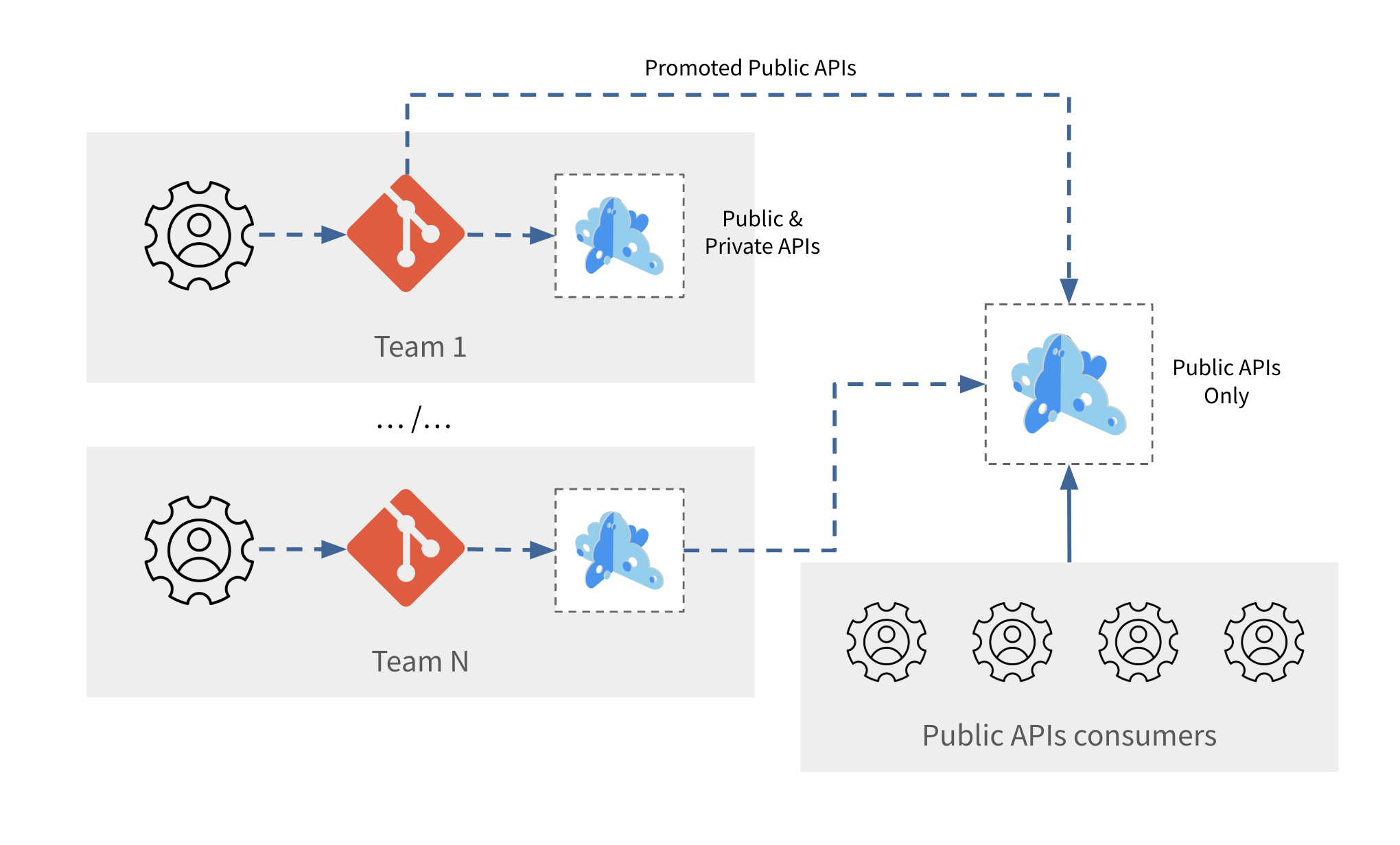
As this pattern can be used in standalone mode, we think it’s best to consider those instances as contributors to a consolidated vision of the available APIs. Hence, you will eventually have to consider some promotion or release process.
Benefits
✅ All the APIs of the region/division: public & private
✅ All the history on what has changed, what has been tested
✅ Ideal for building a comprehensive catalog of the region
✅ Easy to manage role-based access control and delegation
Concerns
🤔 Only the APIs of the region: which makes global discovery hard
❌ Different mock datasets for different use-cases
❌ Different API response times for different use-cases
Microcks at scale
Do you have to choose between one and the other topology? Yes, you definitely have to define priorities to ensure a smooth and incremental adoption. But, ultimately, all of those topologies can play nicely together to handle different situations and stages of your Software Development Life-Cycle.
We see users with great maturity confirming How Microcks fit and unify Inner and Outer Loops for cloud-native development. They deploy it using many topologies in order to have the same tool using the same sources-of-truth throughout the whole lifecycle. That’s what we call: Microcks at scale! 🚀
The schema below represents our vision on how those deployment topologies can be combined to serve the different personas.
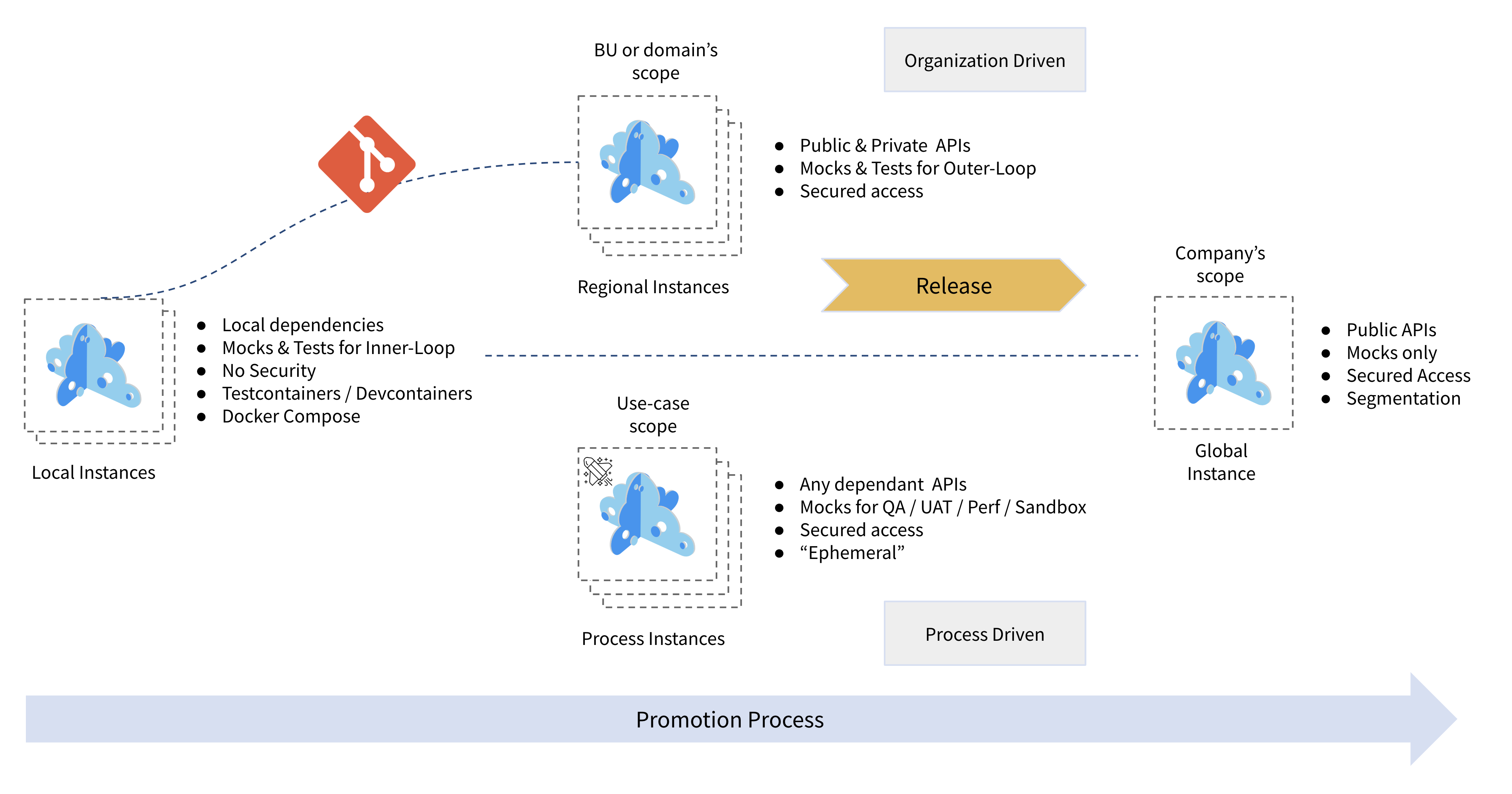
From left to right:
- It all starts with Local Instances integrated into Developers Inner Loop flow. It eases their life in external dependencies management and provides them immediate feedback using contract-testing right in their unit tests,
- Then, Regional Instances may be fed with the promoted API artifacts coming from design iterations. API artifacts contribute to the comprehensive catalog of this BU/domain/application. API Owners can use those instances to launch contract tests on deployed API endpoints and track quality metrics and improvements over time,
- Temporary Process-scoped Instances can be easily provisioned, on-demand, using the regional instances as natural reference catalogs. They allow applying different settings (access-control, datasets, response time,…) depending on the project or use-case needs. Platform Engineers can fully automate this provisioning, in a reproducible way, saving costs vs maintaining comprehensive environments,
- Finally, a globally shared, centralized instance can serve as the consolidated catalog of the organization’s public APIs, offering access to the corresponding mocks to enhance discoverability and tracking of promoted APIs. Enterprise Architects and API consumers will find it useful as the centralized source of truth for all the organization’s APIs.

Still Didn’t Find Your Answer?
Join our community and get the help you need. Engage with other members, ask questions, and share knowledge to resolve your queries and expand your understanding.
Join the community